
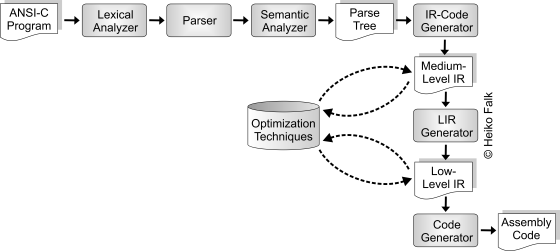
Traditionally, any kind of code optimization is performed by compilers which are specifically designed for dedicated processor architectures. A compiler designed to produce efficient object code includes optimizers. In the following figure, the source code is translated to a medium-level intermediate code, and optimizations that are largely processor-independent are performed on it.
Examples for such optimizations are:
Hereafter, the improved processor-independent code is translated to a low-level form and further optimizations that are mostly processor-specific are applied to it. These optimizations mainly deal with the efficient mapping of a program to machine-specific assembly instructions. This process which is often called code generation is usually decomposed into several phases for which efficient optimization techniques have been proposed:
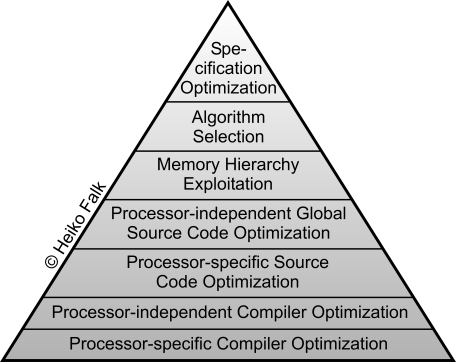
Using the structure of optimizing compilers presented above, the two lowest levels of optimization depicted in the following figure are implemented.
Although being very close to the processor architecture, compilers are often unable to map a source code efficiently to the actual platform. For example, it is very complicated to express a saturated addition in an ANSI-C program:
result = var1 + var2;
if (((var1 ^ var2) & 0x80000000) == 0)
if ((result ^ var1) & 0x80000000)
result = var1 < 0 ? 0x80000000 : 0x7fffffff;
As a consequence, a compiler is unable to recognize such code structures and to generate efficient assembly code, although processors like the TI C6x DSP are able to perform a saturated addition using one machine instruction. Hence, very inefficient control flow dominated machine code is generated during compilation for the given example.
In order to overcome this problem, it is a common technique that compilers provide the programmer with intrinsics (also known as compiler known functions). Using intrinsics, particular features of a processor can be made visible to the programmer. The compiler maps a call to an intrinsic not to a regular function call, but to a fixed sequence of machine instructions. Thus, intrinsics can be considered as source-level macros without any calling overhead. For example, the complex code shown above implementing a saturated addition can be replaced by the intrinsic result = _sadd(var1, var2); using the TI C6x compiler. This way, the compiler is able to replace the entire C fragment by a single instance of the SADD machine instruction.
The optimization of the global memory accesses of an application is crucial for achieving low power systems, because it has been shown that between 50% and 80% of the power in embedded multimedia systems is consumed by memory accesses. The goal of the so-called Data Transfer and Storage Exploration methodology (DTSE) is on the one hand to minimize the storage requirements of embedded applications so as to reduce the absolute amount of memory needed to execute the application. On the other hand, the locality of data memory accesses is optimized at a very high global level in order to achieve a high utilization of small energy-efficient memories which are close to the processor. The DTSE methodology consists of the following steps:
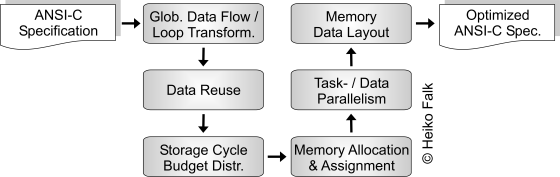
In the beginning, a memory oriented data flow analysis is performed followed by global data flow and loop transformations in order to reduce the required amount of background memories. Hereafter, data reuse transformations exploit a distributed memory hierarchy. Storage cycle budget distribution is performed in order to determine the bandwidth requirements and the balancing of the available cycle budget over the different memory accesses in the algorithmic specification. The goal of the memory hierarchy layer assignment phase is to produce a netlist of memory units from a memory library as well as an assignment of signals to the available memory units. For multi-processor systems, a task-/data-parallelism exploitation step takes place minimizing the communication and storage overhead induced by the parallel execution of subsystems of an application. Finally, data layout transformations (e.g. in-place mapping) help to increase the cache hit rate and to reduce the memory size by storing signals with non-overlapping lifetimes in the same physical memory location.
The DTSE steps described above will typically significantly increase the addressing complexity of transformed applications, e.g. by introducing more complex loop bounds, index expressions, conditions etc. Since this computational overhead is neglected by DTSE, the memory optimized system, despite being more power efficient, will suffer a severe performance degradation. Typical examples show that the runtime performance degrades by a factor of five or six after DTSE.
Parts of the additional complexity introduced by DTSE can be removed by source code optimizations for address optimization (ADOPT). Here, an algebraic cost minimization is performed first minimizing the number of operation instances. The goal is to find factorizations of addressing expressions in order to reuse computations as much as possible.
A very high penalty is caused during DTSE by the frequent insertion of non-linear addressing expressions containing modulo or division operators. Since these are usually not supported by the instruction sets of embedded processors, they are realized by calls to software routines of system libraries. Modulo and division can be replaced by variables serving as accumulators in the following way:
| |
|
int jdiv6=0, jmod6=0; |
| for (j=0; j |
|
for (j=0; j |
| a[j/6][j%6] = ...; | -> | if (jmod6 >= 6) { |
| |
|
jmod6 -= 6; jdiv6++; } |
| |
|
a[jdiv6][jmod6] = ...; } |
Nevertheless, the increased amount of addressing arithmetic is not the only kind of overhead introduced by DTSE. Control flow aspects have not yet been targeted at all in the context of data optimization. For this reason, the source code optimization techniques presented on these pages explicitly focus on this area of research.
The goals of the work presented in the following are:
The techniques presented on this pages can be classified as processor-independent global source code optimizations. Although motivated by different architectural properties (e.g. instruction pipeline or address generation units), these optimization techniques do not take e.g. different pipeline layouts or the potential support of modulo addressing into account. For this reason, one of the main contributions of these optimizations is their independence of actual processor architectures. The provided experimental results demonstrate that various different processor architectures benefit by comparable orders of magnitude. These analogies between different processors underline the high quality of the optimizations independently of actual architectures.
The optimizations presented in the following bridge the gap between the techniques effectively exploring memory hierarchies and those focusing on a dedicated hardware. For example, the intensive optimization of data transfers and memory hierarchies implicitly leads to a degradation of the control flow of an embedded application. For this reason, another important contribution of this work is its concentration on control flow aspects in data flow dominated embedded software.
In order to meet the goals of automated optimization of runtimes and energy consumption, basic optimization strategies which are rather unconventional in the classical compiler construction are utilized. These include genetic algorithms and geometrical polytope models. Using such powerful techniques allows to solve complex code optimization problems for which good heuristics are out of sight. Although these basic strategies are quite complex, all source code optimizations have proven to be highly efficient so that times elapsed during code optimization are negligible.
As will be shown experimentally, these approaches for source code optimization achieve significant improvements in code quality. Code quality is quantified using numerous existing processors which are available in real hardware. The collection of results bases on measurements of the physical processor hardware. Time consuming and imprecise software simulations were avoided to a large extent. Since another contribution of this work is to provide optimization techniques that work in practice, mostly all optimizations are fully automated and applied to real-life embedded software and processors.