
Loop Unrolling is a well-known optimization requiring sophisticated control mechanisms. It replicates the body of a loop a number of times and adjusts the loop control accordingly. The number of replications is called the unrolling factor u and the original loop is often termed rolled loop. If the loop iteration count for a rolled loop is not an integral multiple of u, additional code must be generated to correctly handle left-over loop iterations. The main benefits of loop unrolling are similar to those of function inlining:
The main drawbacks of unrolling are the inherent code size increases potentially augmenting I-cache capacity misses, and additional spill code if the working set of registers of an unrolled loop does no longer fit into a processor's register file. Thus, the central question of loop unrolling is which unrolling factor to use per loop. The unrolling factor depends on several parameters, like e.g., the iteration count of a loop, I-cache memory constraints and an approximation of spill code generation.
Due to lacking sophisticated loop analyses, most compilers only use a constant, small unrolling factor (usually 2 or 4) which does not sufficiently exploit the optimization potential. In contrast, the WCC compiler uses its integrated polyhedral loop analyzer which is extended to also support context-sensitive loop iteration counts. In many real-life applications, loop bounds depend on function parameters, i.e., the bounds are variable and depend on the context in which a function is called. Simple loop analyzers only support purely constant loop bounds and thus can not handle such classes of loops. WCC's loop analyzer uses parameterized polyhedra to model loops depending on function parameters. Thus, this loop analyzer provides many different iteration counts per single loop, depending on a loop's contexts.
Within WCC, loop unrolling takes place at C code level in ICD-C. To circumvent negative unrolling effects due to I-cache thrashing, each loop is translated into assembly code. For assembly code, it is easy to determine the size of the loop header and of its body in bytes. Using WCC's back-annotation, this data is shifted back to the C code level. By combining these code sizes with I-cache related data from WCC's memory hierarchy infrastructure, WCC's unrolling is able to estimate how large a loop unrolled by factor u will become at assembly level so that increases of I-cache misses are avoided.
The possibly many iteration counts per loop provided by WCC's loop analyzer are finally used to estimate whether unrolling leads to the generation of additional spill code during register allocation. For this purpose, a rolled loop L is virtually unrolled by a factor u being equal to the smallest common prime factor (SCPF) of all possible iteration counts of L. The resulting unrolled loop is denoted LSCPF. For both L and LSCPF, assembly code is generated and the amount of spill code in both loops is counted. If LSCPF contains more spill code then u times L's amount of spill code, unrolling led to the generation of additional spill code. Again, this spilling-related data is back-annotated into WCC's front-end. Likewise, WCC performs a WCET analysis of each loop LSCPF and also back-annotates this WCET data.
By combining the available information about iteration counts, code sizes, I-cache properties, spill code and WCETs, the final unrolling factor uLfinal is computed for each loop L. Therefore, all innermost loops of a program are considered as unrolling candidates which do not lead to increased spill code. Each unrolling candidate is assigned a profit. The profit represents the expected WCET reduction and code size increase when the loop is unrolled by factor uLfinal. Loops with larger profits promise a higher benefit and are thus unrolled first as long as no additional I-cache misses are expected. Loops with negative profit will likely have a negative impact on the WCET and are thus excluded from unrolling.
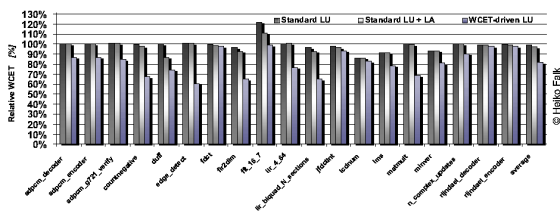
The above figure shows the WCETs for different unrolling strategies and 19 real-life benchmarks. The first bar per benchmark denotes a standard, WCET-unaware loop unrolling (LU) as it can be found in many compilers nowadays. Unrolling is done as long as the unrolled loop is not larger than 50 ANSI-C expressions. Furthermore, only a simple, context-insensitive loop analysis is used here. The second bar per benchmark combines the WCET-unaware standard LU with WCC's context-sensitive loop analyzer (LA). The third bar represents WCC's WCET-aware LU, including its context-sensitive LA. All results are given as a percentage, with 100% corresponding to the benchmarks' WCET if no unrolling is done. All results are generated using WCC's highest optimization level -O3 and assuming a 2 kB I-cache.
As can be seen, standard LU has minimal positive effects on WCETs. Only for few benchmarks, significant WCET reductions were achieved. On average over all benchmarks, standard LU reduces WCETs by less than 1%. Integrating WCC's sophisticated loop analysis into standard loop unrolling slightly improves the average WCETs of all benchmarks by 2.9%. Notably improved results are achieved by the proposed WCET-aware LU. WCET reductions of up to 39.5% were obtained. On average, WCET-aware loop unrolling reduces WCETs by 18.3%.
Combining Worst-Case Timing Models, Loop Unrolling, and Static Loop Analysis for WCET Minimization