
Caches are widely used to bridge the increasingly growing gap between processor and memory performance. They store copies of frequently used parts of the slow main memory for faster access. In order to increase the effectiveness of caches, a WCET-driven cache-aware memory content selection algorithm can be employed. Such an algorithm allocates functions whose WCET highly benefits from a cached execution to cached memory areas. Vice versa, rarely used functions which do not benefit from a cached execution are allocated to non-cached memory areas. As a result of this, unfavorable functions w. r. t. a program’s WCET can not evict beneficial functions from the cache. This can lead to a reduced cache miss ratio and a decreased WCET.
Our WCC compiler is the first one which includes a technique for a WCET-driven cache-aware memory content selection. The main contributions of our algorithm are that it
Many embedded systems have parameterizable caches and memory layouts which allow that parts of the address space can be included or excluded from caching. Our WCET-aware compiler exploits such a memory system and allocates functions to cached or non-cached memory regions. This strategy can ensure that functions which highly benefit from a cached execution can not be evicted by functions with a lower benefit.
Since even local code modifications can have a strong impact on the WCET of other parts of a program, the impact is hardly predictable without performing a complete WCET-analysis. To deal with this handicap, we developed a greedy approach which moves single function between cached and non-cached memory areas and evaluates the influence on the WCET of a program.
If moving a function to a different memory area results in a WCET reduction, the new assignment of functions to cached and non-cached memory areas serves as starting point for the next iteration. But if the WCET is increased, the last modification is rolled back in order to guarantee that the optimized program is never worse than the original one w.r.t. its WCET.
The algorithm terminates if all functions are either decided to be allocated to a cached or non-cached memory area. So, finally we have a set of functions which should be cached and a set of functions to be excluded from caching.
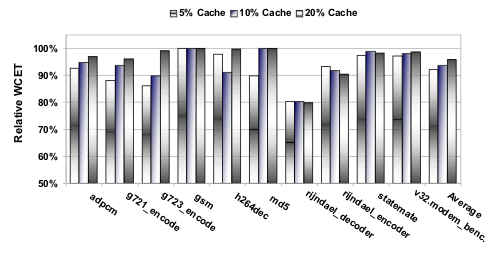
The above figure shows the impact of our WCET-driven Cach-aware memory content selection on the WCET estimates of 10 largest applications from the MRTC, MediaBench, UTDSP and DSPstone benchmark suites.
Today's embedded systems are equipped with main memories in megabyte ranges and caches typically ranging from 1 kB up to 16 kB or at most 32 kB. Due to this ratio of small cache compared to a large main memory, we artificially limited the cache sizes to 5, 10 and 20% of the program's overall code size. This guarantees, that we use a similar ratio of cache size to program size for all optimizations and static WCET analyses, found in current embedded systems in order to generate comparable results.
For each benchmark, each of the three bars represent the results for different cache sizes. The bars depict the estimated WCET of the optimized program computed by the static WCET analyzer relative to the estimated WCET if the benchmark is executed with all functions located in a cached memory region.
Our algorithm was able to reduce the estimated WCET of the benchmarks by up to 19.5% for 5% and 10% cache size for the rijndael_decoder. For the same benchmark, we were able to achieve a WCET reduction of 20.1% for 20% cache size. The reasons why the worst-case performance of benchmark gsm could not be improved are twofold. First, the loop of a filter function which consumes about 95% of the program's estimated WCET amounts to only 3% of the program size and fits into all considered cache sizes. Second, the programs control flow is highly serial with only few branches. Thus, only few cache conflict misses occur and the best performance is achieved if all functions reside in a cached memory area during execution.
On average, we were able to reduce the estimated WCET for all benchmarks by 8% for the smallest considered cache size and by 6 and 4% for 10% and 20% cache size, respectively.