
A summary of the effects of all source code optimizations presented on these pages on the runtime of a realistic benchmark application (CAVITY) for a large series of different processors is given in the following diagram:
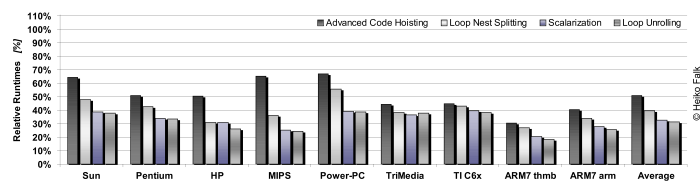
This figure shows the runtimes of the benchmark for each phase of the entire sequence of source code optimizations. The optimizations were applied in the following order:
In order to enable the easy comparison of the various results, the runtimes of the above figure are given relatively as a percentage of the original unoptimized source code version whith is highlighted by the 100% base line.
As can be seen, considerable speed-ups are achieved by the optimization sequence for all studied processors. These total gains vary between 61.5% for the Power-PC and up to 81.7% for the ARM7 in thumb mode. The average speed-up for all processors amounts to 68.8% which is more than a factor of three of improvement. Although individual optimizations contribute to a different extent to the measured improvements, these results clearly demonstrate that the optimizations presented here are highly independent of actual processor architectures.
These large speed-ups mainly originate from the reductions of total instruction executions achieved by all optimizations. Loop Nest Splitting heavily reduces executions of if-statements and complex conditions. Advanced Code Hoisting minimizes address code execution which is also targeted by the ring buffer optimizations.
Since it is well-known that transfers of instructions and data between background memories and a processor contribute most to the total energy dissipation, the entire sequence of source code optimizations presented here also leads to massive energy savings. This fact is depicted in the following figure:
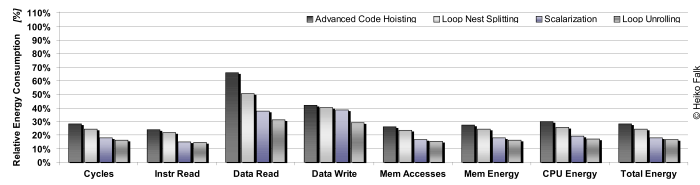
This figure shows various characteristics of the optimized CAVITY benchmark for an ARM7TDMI processor. It includes the cycle count, the amounts of reading and writing instruction and data memory accesses, the total number of memory accesses and the energy consumed by memory, ARM7 and the total system. All these values were generated using the Energy-Aware C Compiler developed at LS XII. Results are given in a relative way where the highlighted base line of 100% denotes the characteristics of the unoptimized CAVITY application.
As can be seen from column Mem Accesses, the entire optimization sequence leads to a reduction of memory accesses by 84.4%. This reduction is due to huge minimization of instruction executions on the one hand. On the other hand, data transfers between ARM7 and memory are also reduced significantly. As a consequence, the energy consumed by the memory and by the ARM7 itself is reduced by a similar order of magnitude. Total energy savings of 82.9% were measured after all source code optimizations presented on these pages.
Besides the achieved savings in execution time and energy dissipation, the main contributions of the optimization techniques presented here are: