
The GNU R language is very popular in the domain of statistics. Its functional character supports the rapid development of statistical algorithms and analyses. Statisticians around the world profit from the immense R package archive CRAN where researchers offer their algorithms in form of R programs for free usage.
One of the disadvantages of R is that programs have to be evaluated and processed by a runtime interpreter. Such an interpretation requires a lot of time and delays the execution. Thus, a lot of computing power is wasted compared to imperative languages like ANSI C, which can be automatically optimized and translated to machine code by a sophisticated compiler.
In the following, we present some ideas for optimization techniques which allow a significant performance increase of R programs:
For most imperative programming language like C, sophisticated compiler toolchains are existing. In order to avoid a time consuming interpretation of GNU R programs, we also propose such a compiler toolchain for R which automatically optimize and translate a program to efficient machine code.
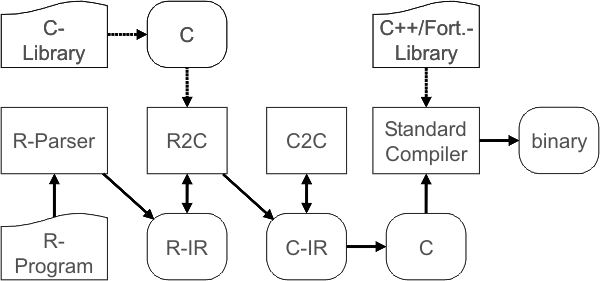
The overall structure of the proposed GNUR R compiler toolchain is depicted in the figure above. Rounded boxes denote representations of the program to optimize at different abstraction levels. Squared boxed represent the different compiler tools working on each stage of the compilation process:
In order to demonstrate the effectiveness of our proposed toolchain, a case study where we manually applied the standard optimizations common subexpression elimination (CSE) and dead code elimination (DCE) on GNU R code was performed. Additionally, code snippets were manually translated from R to C code and finally to machine code in order to demonstrate the effectiveness of a possible R compiler toolchain.
The common subexpression elimination is an optimization which removes redundancy in form of subexpressions from the code. It searches equal subexpressions which always evaluate to the same value and replaces the repeated computation by a variable holding the precomputed value.
strMCMC(), which is an R package for estimating graphical model by employing a Markov Chain Monte Carlo approach, serves as example. Consider the following R code snippet before CSE:
x[ which( y[z[1],] == 1 ) ] x[ which( y[z[1],] == 1 ) ] – 1;
By manually applying CSE, superfluous recomputations are removed:
cse x[ cse ]
The dead code elimination is an optimization which removes code which is never executed. For instances if it can be evaluated at compile time that a condition always evaluates false, the complete condition statement can be removed.
Here, too, strMCMC() serves as example. Consider the following R code snippet before applying DCE:
...
for (i in 1:d2) {
if (!is.null(tmp))
ans[[i]] }
...
Since it can be determined at compile time that for each call of the which() function x is always logical, the if expression can be removed:
...
for (i in 1:d2) {
if (!is.null(tmp))
ans[[i]] }
...
The commonly used rda package is used as example for translating R to C code. It turned out, that a for loop inside the heavily used apply() function was the hotspot of the algorithm.
The following code snippet shows the mentioned loop which is manually translated to equivalent C code:
...
for (i in 1:d2) {
if (!is.null(tmp))
ans[[i]] }
...
The resulting C code is translated to efficient machine code and will be called using R's .C interface.
By applying the optimization CSE, the runtime of the strMCMC() function can be decreased by 10% whereas DCE can decrease the execution runtime by up to 5%. The translation of the time consuming for loop inside the apply() function can decrease the overall runtime of the rda package by 70%. The translated code snipped in itself outperforms the R code by a factor of up to 90!